Abstract
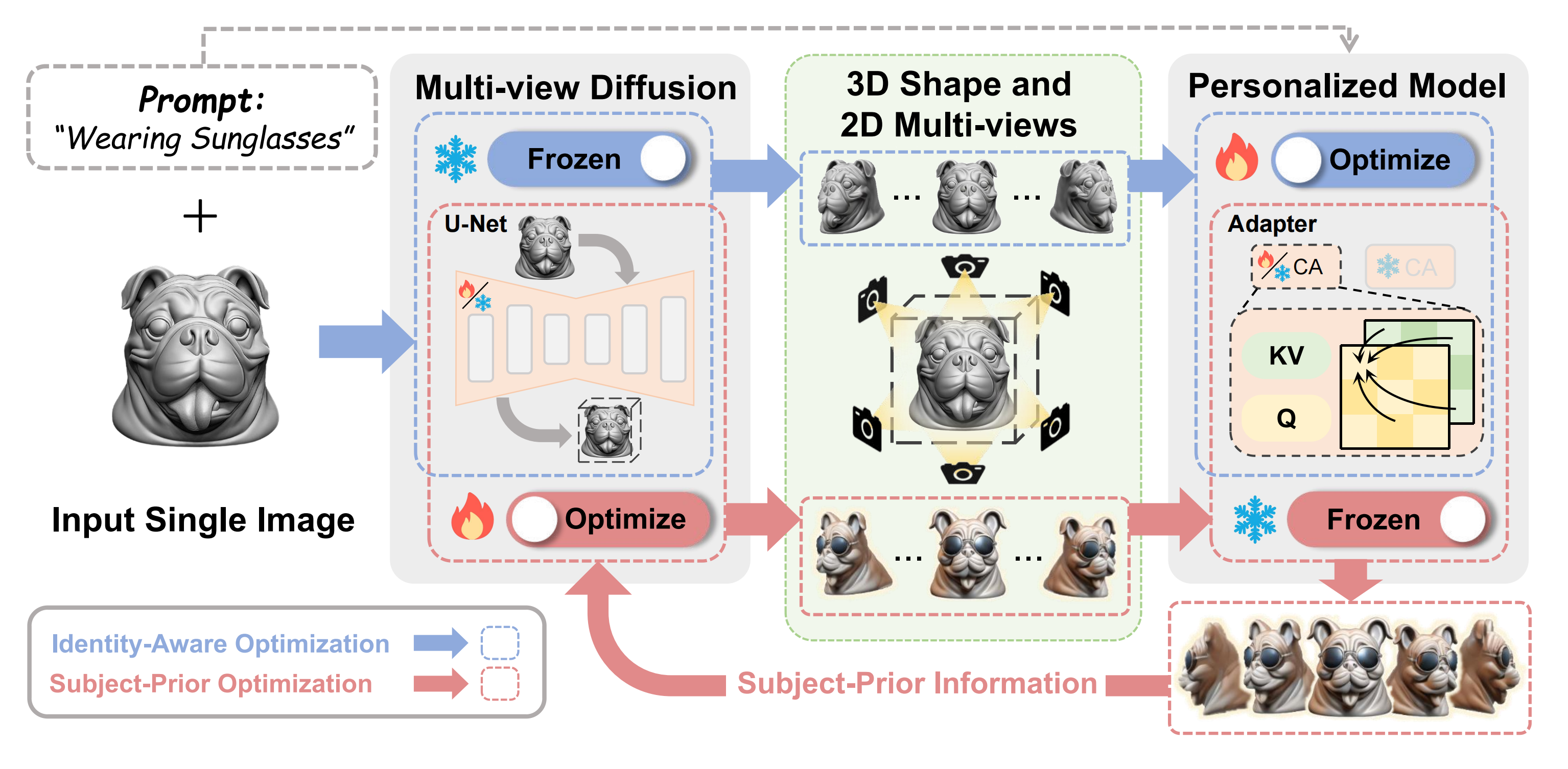
Recent years have witnessed the strong power of 3D generation models, which offer a new level of creative flexibility by allowing users to guide the 3D content generation process through a single image or natural language. However, it remains challenging for existing 3D generation methods to create subject-driven 3D content across diverse prompts. In this paper, we introduce a novel 3D customization method, dubbed Make-Your-3D that can personalize high-fidelity and consistent 3D content from only a single image of a subject with text description within 5 minutes. Our key insight is to harmonize the distributions of a multi-view diffusion model and an identity-specific 2D generative model, aligning them with the distribution of the desired 3D subject. Specifically, we design a co- evolution framework to reduce the variance of distributions, where each model undergoes a process of learning from the other through identity-aware optimization and subject-prior optimization, respectively. Extensive experiments demonstrate that our method can produce high-quality, consistent, and subject-specific 3D content with text-driven modifications that are unseen in subject image.

Figure 1. Make-Your-3D can personalize 3D contents from only a single image of a subject with text-driven modifications within only 5 minutes, which is 36 x faster than DreamBooth3D.