|
I'm a third-year PhD student in the Department of Electronic Engineering at Tsinghua University . In 2023, I obtained my B.Eng. in the Department of Electronic Engineering, Tsinghua University. My research interest lies in World Model and Spatial Intelligence. I aim to build spatially intelligent AI that can model the world and reason about objects, places, and interactions in 3D space and time. Email / CV / Google Scholar / Github / Twitter
|

|
|
|
*Equal contribution †Project leader |

|
Fangfu Liu*, Kai He* , Tianchang Shen , Tianshi Cao , Sanja Fidler , Yueqi Duan , Jun Gao , Igor Gilitschenski , Zian Wang , Xuanchi Ren Technical Report, 2026 [arXiv] [Code] [Project Page] 
We present γ-World, a generative multi-agent world model that rolls out a single shared environment for multiple independently controllable agents. γ-World introduces Simplex Rotary Agent Encoding for permutation-symmetric agent conditioning, Sparse Hub Attention for efficient cross-agent communication, and a distilled block-causal student for real-time 24 FPS streaming with zero-shot generalization from two to four players. |
|
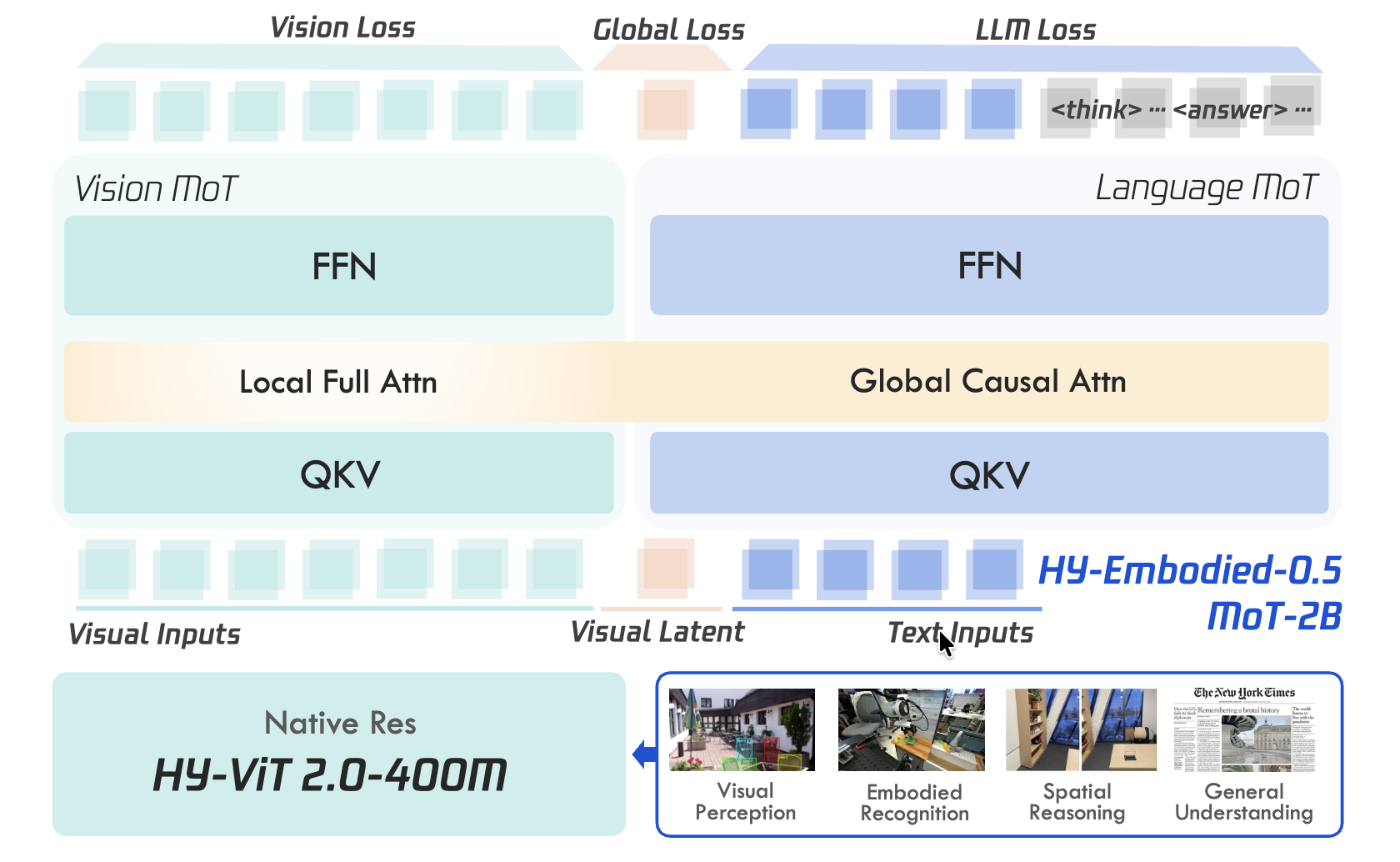
Xumin Yu, Zuyan Liu, Ziyi Wang, He Zhang, Yongming Rao, Fangfu Liu, Yani Zhang, Ruowen Zhao, Oran Wang, Yves Liang, Haitao Lin, Minghui Wang, Yubo Dong, Kevin Cheng, Bolin Ni, Rui Huang, Han Hu, Zhengyou Zhang, Shunyu Yao Technical Report, 2026 [arXiv] [Code] [Project] 
HY-Embodied-0.5 is a family of embodied foundation models built for real-world agents, achieving state-of-the-art performance across 22 benchmarks in visual perception, spatial reasoning, and embodied understanding, with effective downstream robot control. |
|
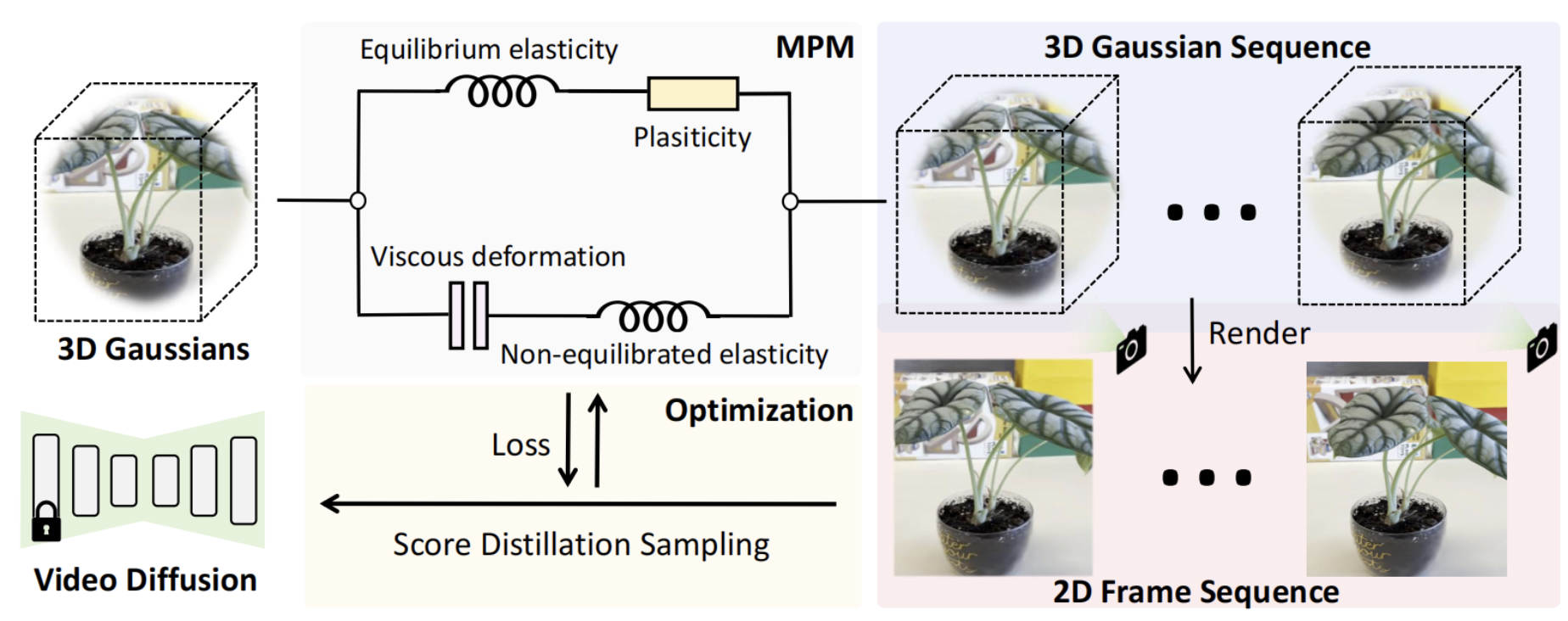
Fangfu Liu*, Hanyang Wang* Shunyu Yao , Shengjun Zhang, Jie Zhou, Yueqi Duan Technical Report, 2024 [arXiv] [Code] [Project Page] 
In this paper, we propose Physics3D, a novel method for learning various physical properties of 3D objects through a video diffusion model. Our approach involves designing a highly generalizable physical simulation system based on a viscoelastic material model, which enables us to simulate a wide range of materials with high-fidelity capabilities. |
|
*Equal contribution †Project leader |
|
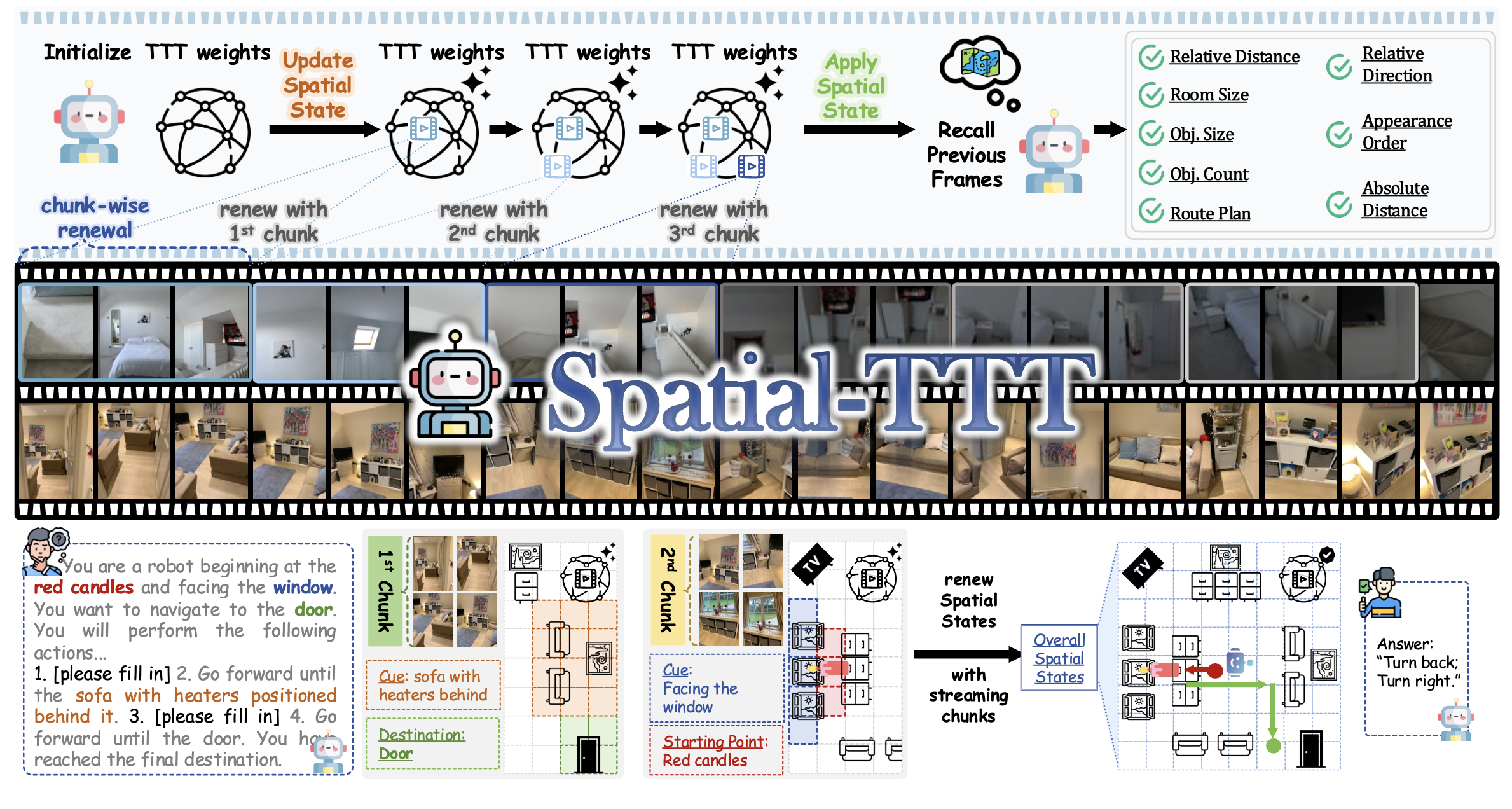
Fangfu Liu*, Diankun Wu* , Jiawei Chi* , Yimo Cai, Yi-Hsin Hung, Xumin Yu , Hao Li , Han Hu , Yongming Rao , Yueqi Duan European Conference on Computer Vision (ECCV), 2026 [arXiv] [Code] [Project Page] 
We propose Spatial-TTT, a framework for streaming visual-based spatial intelligence with Test-Time Training (TTT). Given a visual-based spatial task, our method updates spatial state with streaming chunks then answers the question, achieving state-of-the-art performance on video spatial benchmarks. |
|
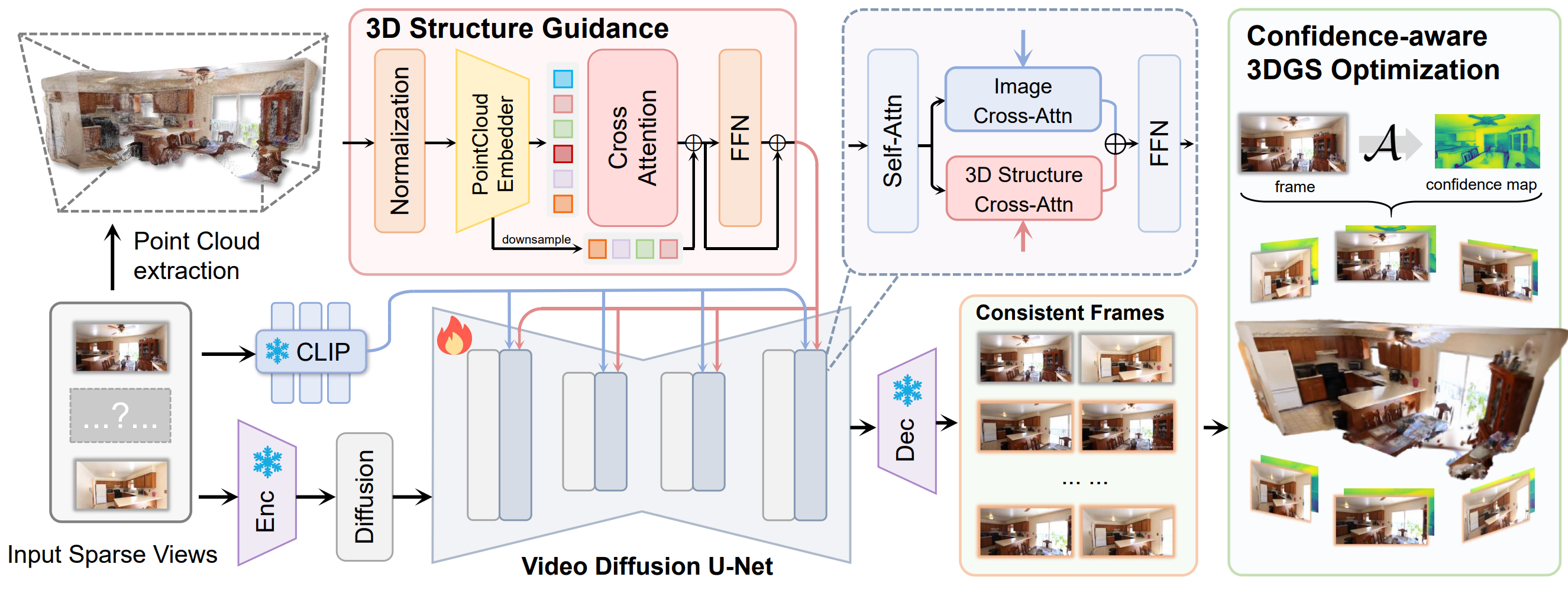
Fangfu Liu*, Wenqiang Sun* , Hanyang Wang* , Yikai Wang , Haowen Sun , Junliang Ye , Jun Zhang , Yueqi Duan IEEE Transactions on Image Processing (TIP), 2025 [arXiv] [Code] [Project Page] 
In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. |
|
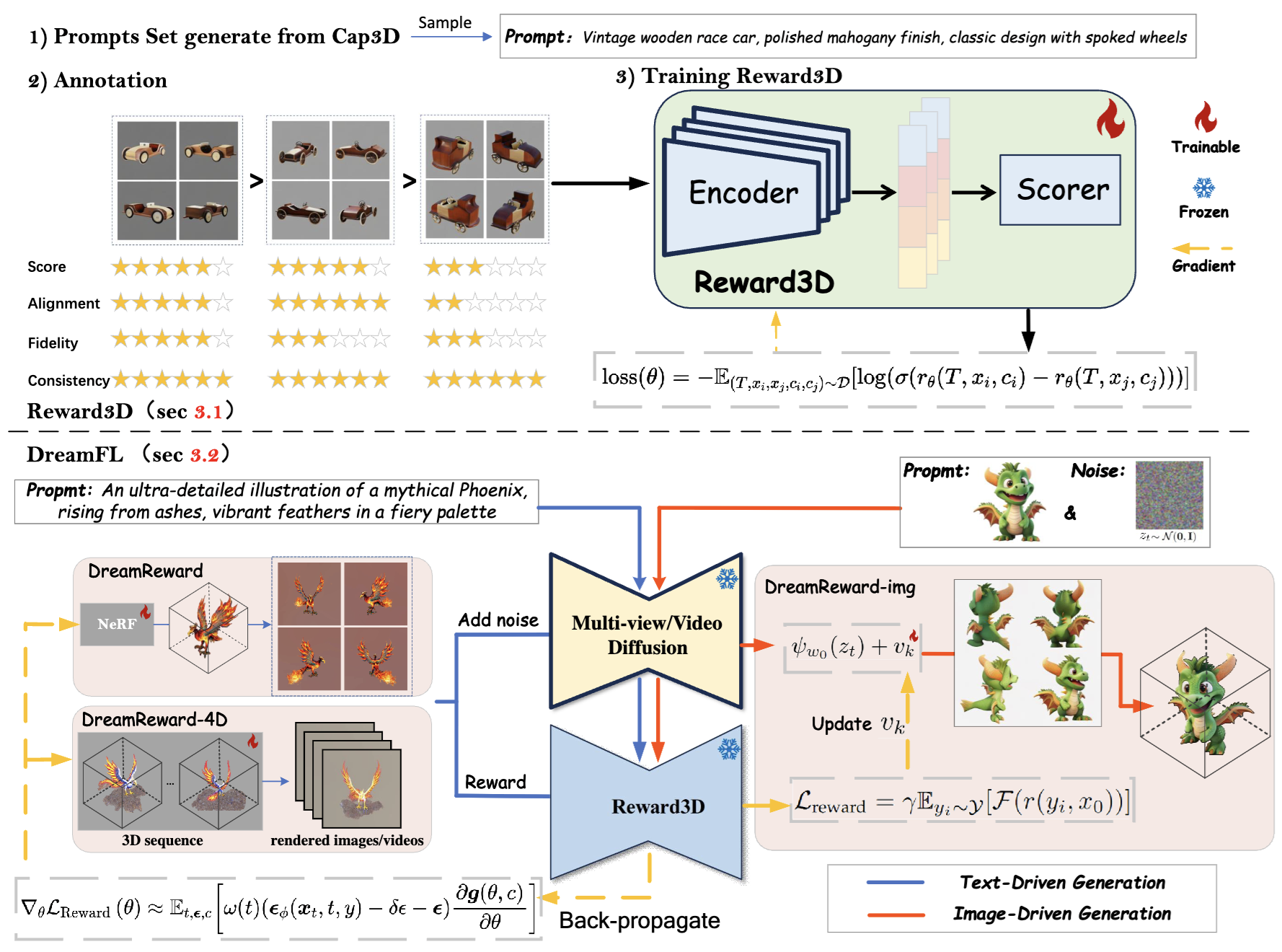
Fangfu Liu, Junliang Ye , Yikai Wang , Hanyang Wang , Zhengyi Wang , Jun Zhu , Yueqi Duan IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [arXiv] [Code] [Project Page] 
We present a comprehensive framework, coined DreamReward-X, where we introduce a reward-aware noise sampling strategy to unleash text-driven diversity during the generation process while ensuring human preference alignment. Our results demonstrate the great potential for learning from human feedback to improve 3D generation. |

|
Diankun Wu*, Fangfu Liu*, Yi-Hsin Hung, Yueqi Duan Conference on Neural Information Processing Systems (NeurIPS), 2025 Spotlight Paper [arXiv] [Code] [Project Page] 
In this paper, we present Spatial-MLLM, a novel framework for visual-based spatial reasoning from purely 2D observations. Unlike conventional video MLLMs which rely on CLIP-based visual encoders optimized for semantic understanding, our key insight is to unleash the strong structure prior from the feed-forward visual geometry foundation model. |

|
Fangfu Liu, Hao Li , Jiawei Chi , Hanyang Wang , Minghui Yang, Fudong Wang, Yueqi Duan IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] 
In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. |

|
Fangfu Liu*, Hanyang Wang* , Yimo Cai, Kaiyan Zhang , Xiaohang Zhan , Yueqi Duan IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] 
We present the generative effects and performance improvements of video generation under test-time scaling (TTS) settings. The videos generated with TTS are of higher quality and more consistent with the prompt than those generated without TTS. |
|
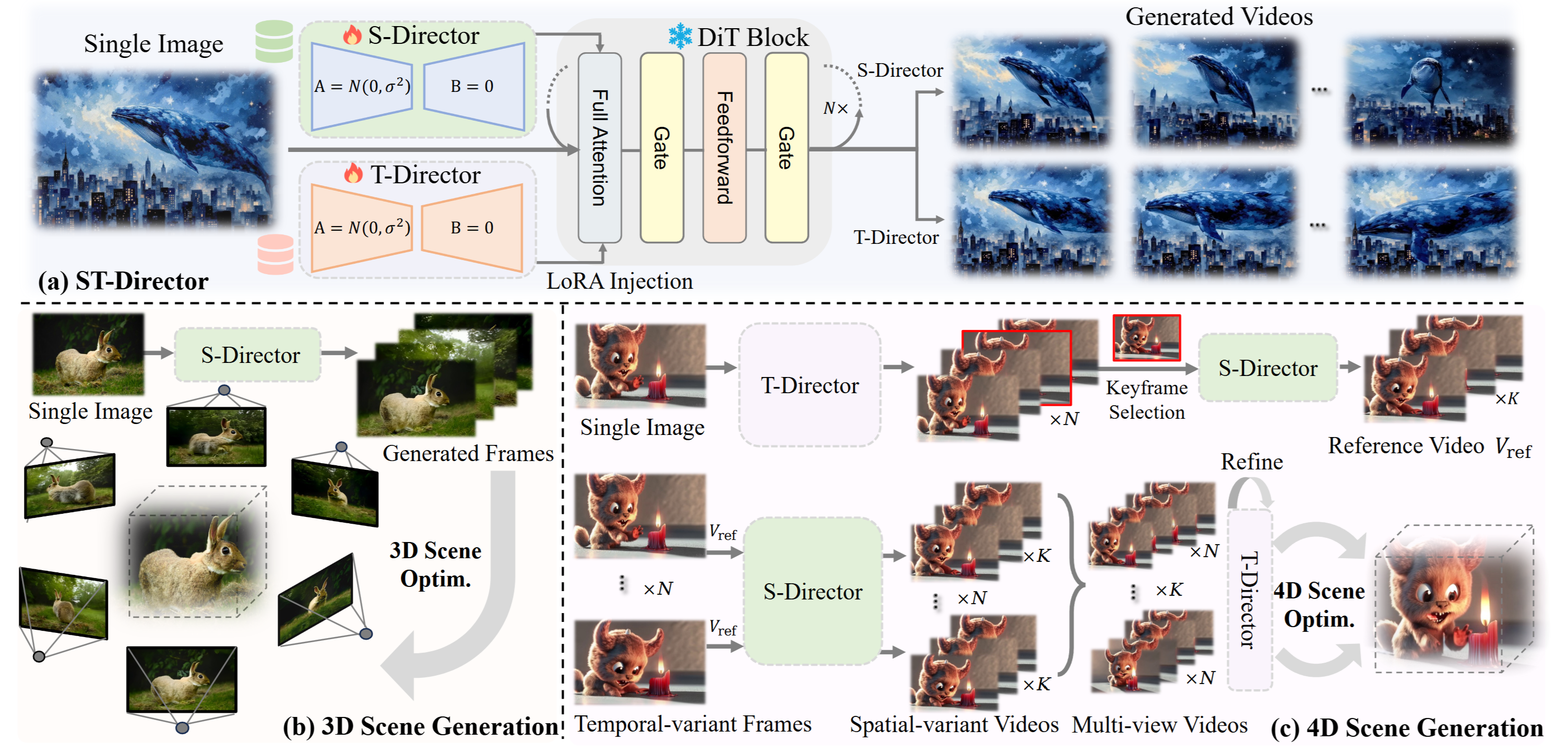
Wenqiang Sun* , Shuo Chen* , Fangfu Liu*, Zilong Chen , Yueqi Duan , Jun Zhang , Yikai Wang IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] 
In this paper, we introduce DimensionX, a framework designed to generate photorealistic 3D and 4D scenes from just a single image with video diffusion. We believe that our research provides a promising direction to create a dynamic and interactive environment with video diffusion models. |

|
Hanyang Wang* , Fangfu Liu*, Jiawei Chi, Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Highlight Paper [arXiv] [Code] [Project Page] 
In this paper, we propose VideoScene to distill the video diffusion model to generate 3D scenes in one step, aiming to build an efficient and effective tool to bridge the gap from video to 3D. |

|
Diankun Wu , Fangfu Liu, Yi-Hsin Hung, Yue Qian, Xiaohang Zhan , Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [arXiv] [Code] [Project Page] In this work, we propose 4D-Fly for fast reconstructing 4D scenes from monocular videos in minutes. Compared to previous methods, our approach achieves 20x speed-up while maintaining comparable or superior reconstruction quality. |

|
Kailu Wu , Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan , Kaisheng Ma Conference on Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] [Project Page] 
In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Unique3D can generate a high-fidelity textured mesh from a single orthogonal RGB image of any object in under 30 seconds. |
|
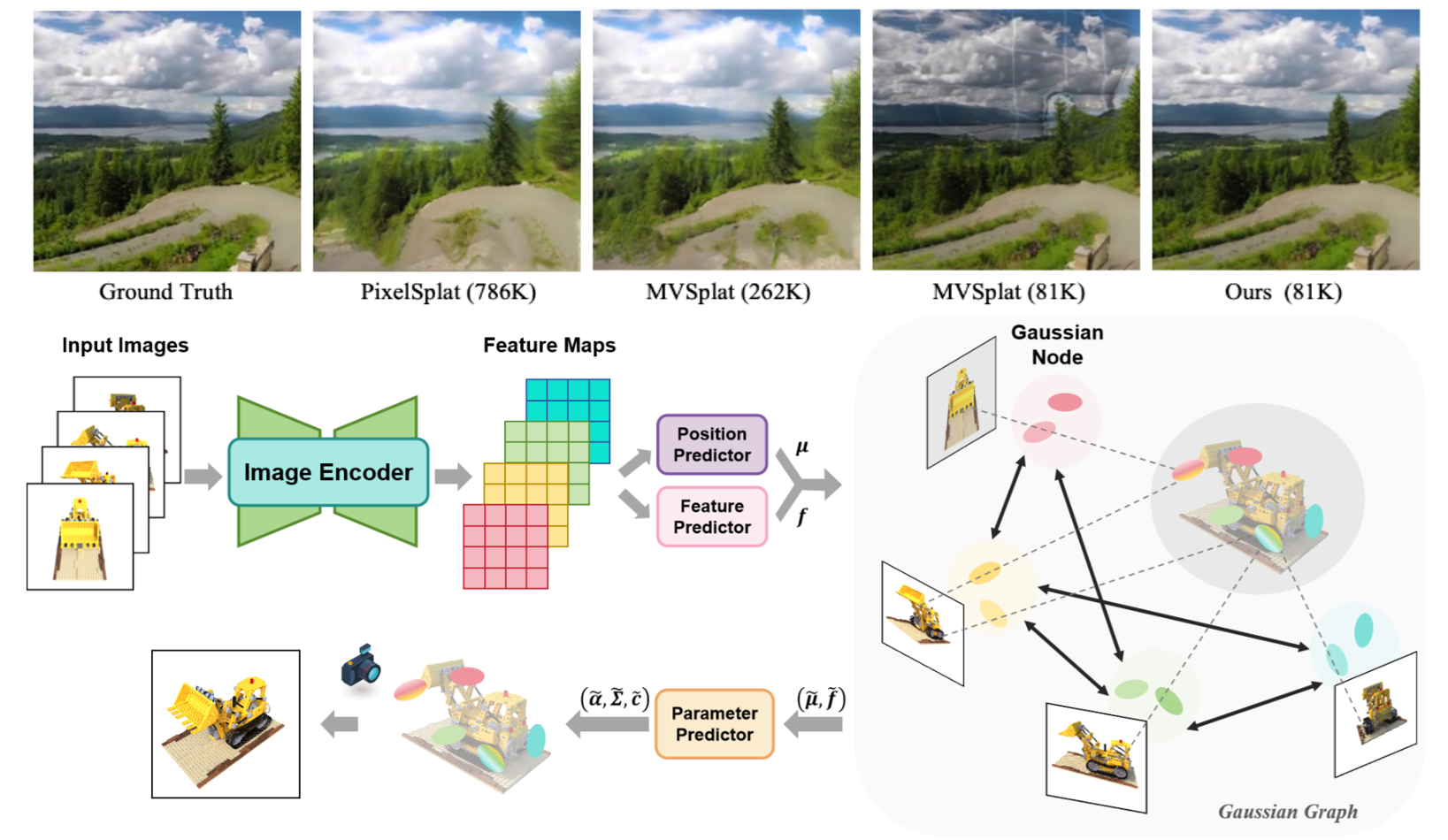
Shengjun Zhang , Xin Fei, Fangfu Liu, Haixu Song, Yueqi Duan Conference on Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] [Project Page] In this paper, we propose Gaussian Graph Network (GGN) to generate efficient and generalizable Gaussian representations. Specifically, we construct Gaussian Graphs to model the relations of Gaussian groups from different views. Compared to the state-of-the-art methods, our model uses fewer Gaussians and achieves better image quality with higher rendering speed. |
|
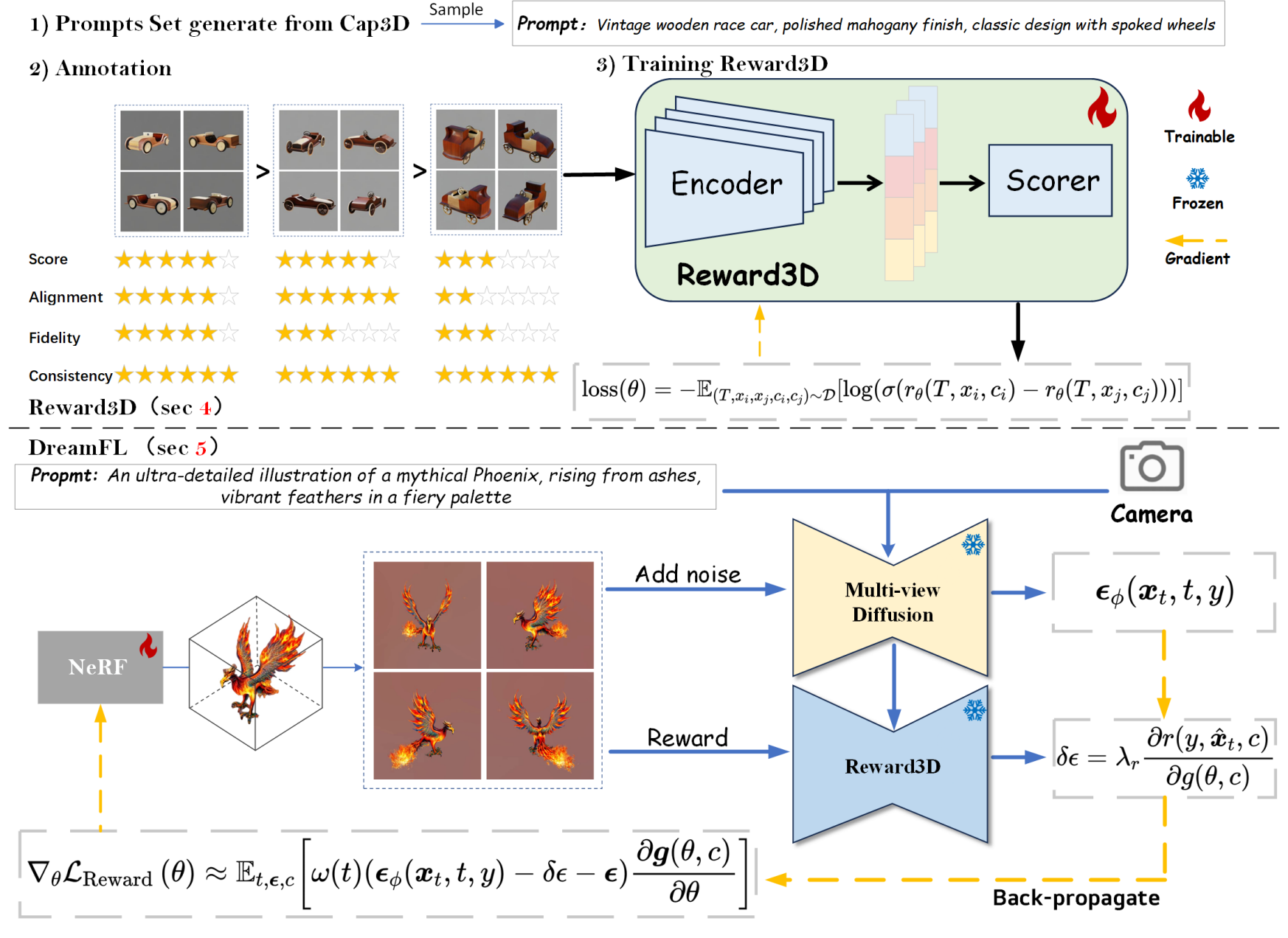
Junliang Ye* , Fangfu Liu*, Qixiu Li, Zhengyi Wang , Yikai Wang , Xinzhou Wang, Yueqi Duan , Jun Zhu European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page]
In this work, We propose the first general-purpose human preference reward model for text-to-3D generation, named Reward3D. Then we further introduce a novel text-to-3D framework, coined DreamReward, which greatly boosts high-text alignment and high-quality 3D generation through human preference feedback. |

|
Fangfu Liu, Hanyang Wang, Weiliang Chen, Haowen Sun, Yueqi Duan European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page] 
We introduce a novel 3D customization method, dubbed Make-Your-3D that can personalize high-fidelity and consistent 3D content from only a single image of a subject with text description within 5 minutes. |

|
Fangfu Liu, Diankun Wu, Yi Wei , Yongming Rao , Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [arXiv] [Code] [Project Page] 
We propose Sherpa3D, a new text-to-3D framework that achieves high-fidelity, generalizability, and geometric consistency simultaneously. Extensive experiments show the superiority of our Sherpa3D over the state-of-the-art text-to-3D methods in terms of quality and 3D consistency. |
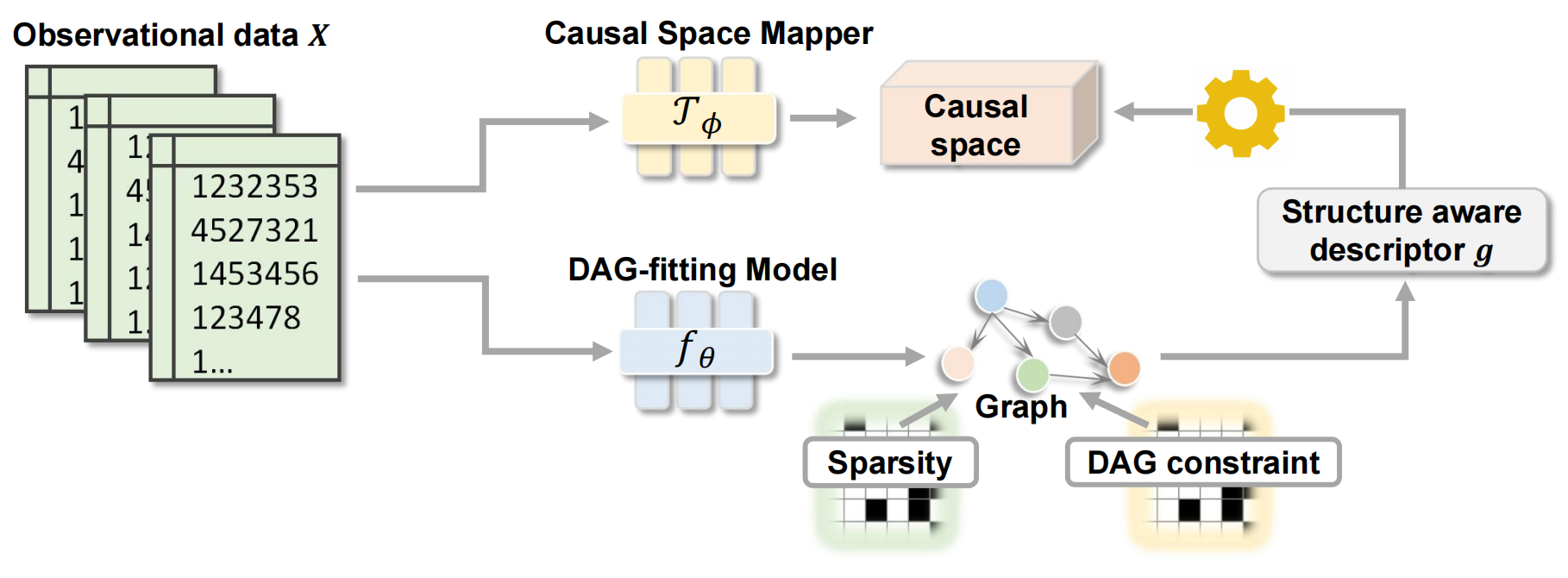
|
Fangfu Liu, Wenchang Ma, An Zhang , Xiang Wang , Yueqi Duan , Tat-Seng Chua ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2023 Oral Presentation [arXiv] [Code] [Project Page] we propose a dynamic causal space for DAG structure learning, coined CASPER, that integrates the graph structure into the score function as a new measure in the causal space to faithfully reflect the causal distance between estimated and groundtruth DAG. |
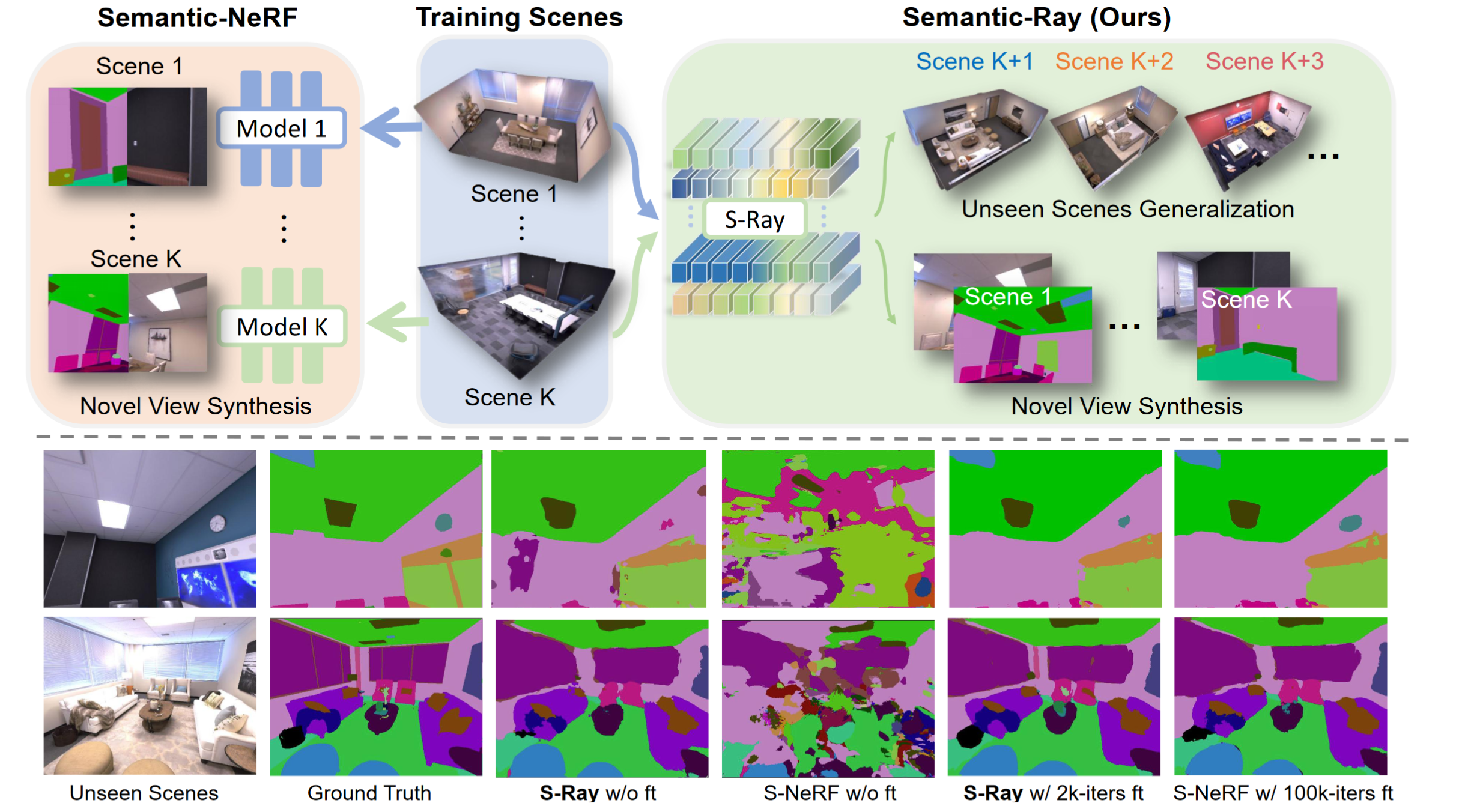
|
Fangfu Liu, Chubin Zhang, Yu Zheng, Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [arXiv] [Code] [Project Page] 
We propose a neural semantic representation called Semantic-Ray (S-Ray) to build a generalizable semantic field, which is able to learn from multiple scenes and directly infer semantics on novel viewpoints across novel scenes. |
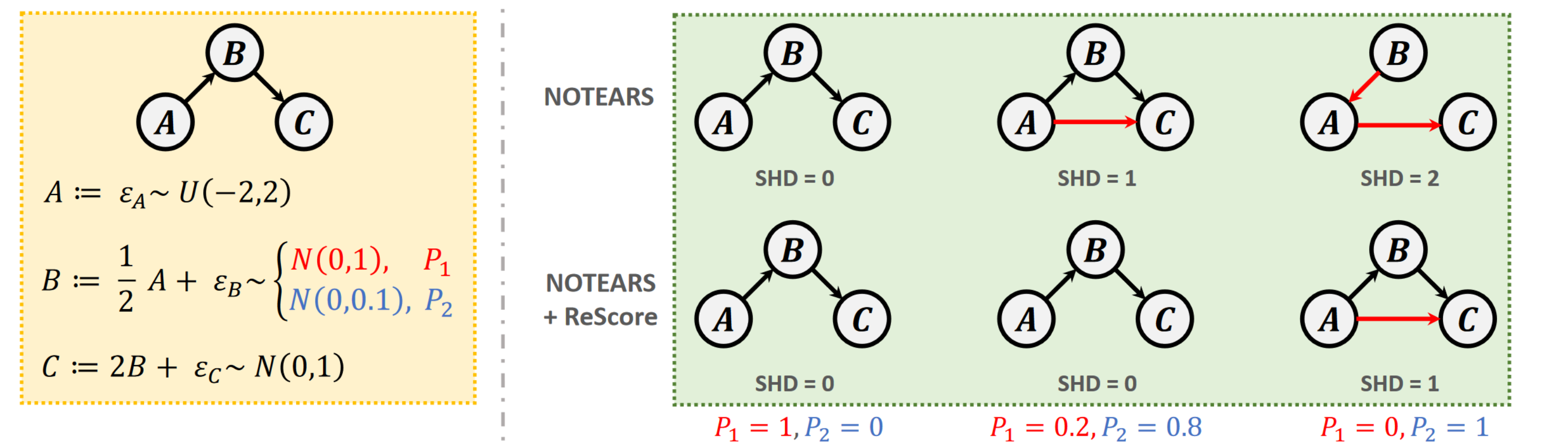
|
An Zhang, Fangfu Liu, Wenchang Ma, Zhibo Cai, Xiang Wang , Tat-Seng Chua International Conference on Learning Representations (ICLR), 2023 [arXiv] [Code] [Project Page] We propose ReScore, a simple-yet-effective model-agnostic optimzation framework that simultaneously eliminates spurious edge learning and generalizes to heterogeneous data by utilizing learnable adaptive weights. |
|
|
|
|
|
|