Abstract
In this paper, we aim to learn a semantic radiance field from multiple scenes that is accurate, efficient and
generalizable. While most existing NeRFs target at the tasks of neural scene rendering, image synthesis and multi-
view reconstruction, there are a few attempts such as Semantic NeRF that explore to learn high-level semantic
understanding with the NeRF structure. However, Semantic-NeRF simultaneously learns color and semantic label from a
single ray with multiple heads, where single rays fail to provide rich semantic information. As a result, Semantic
NeRF relies on positional encoding and needs to train one independent model for each scene. To address this, we
propose Semantic Ray (S-Ray) to fully exploit semantic information along the ray direction from its multi-view
reprojections. As directly performing dense attention over multi-view reprojected rays would suffer from heavy
computational cost, we design a Cross-Reprojection Attention model with consecutive radial and cross-view sparse
attentions, which decomposes contextual information along reprojected rays and cross multiple views and then collects
dense connections by stacking the modules. Experiments show that our S-Ray is able to learn from multiple scenes, and
it presents strong generalization ability to adapt to unseen scenes.
Generalizable Semantic Field
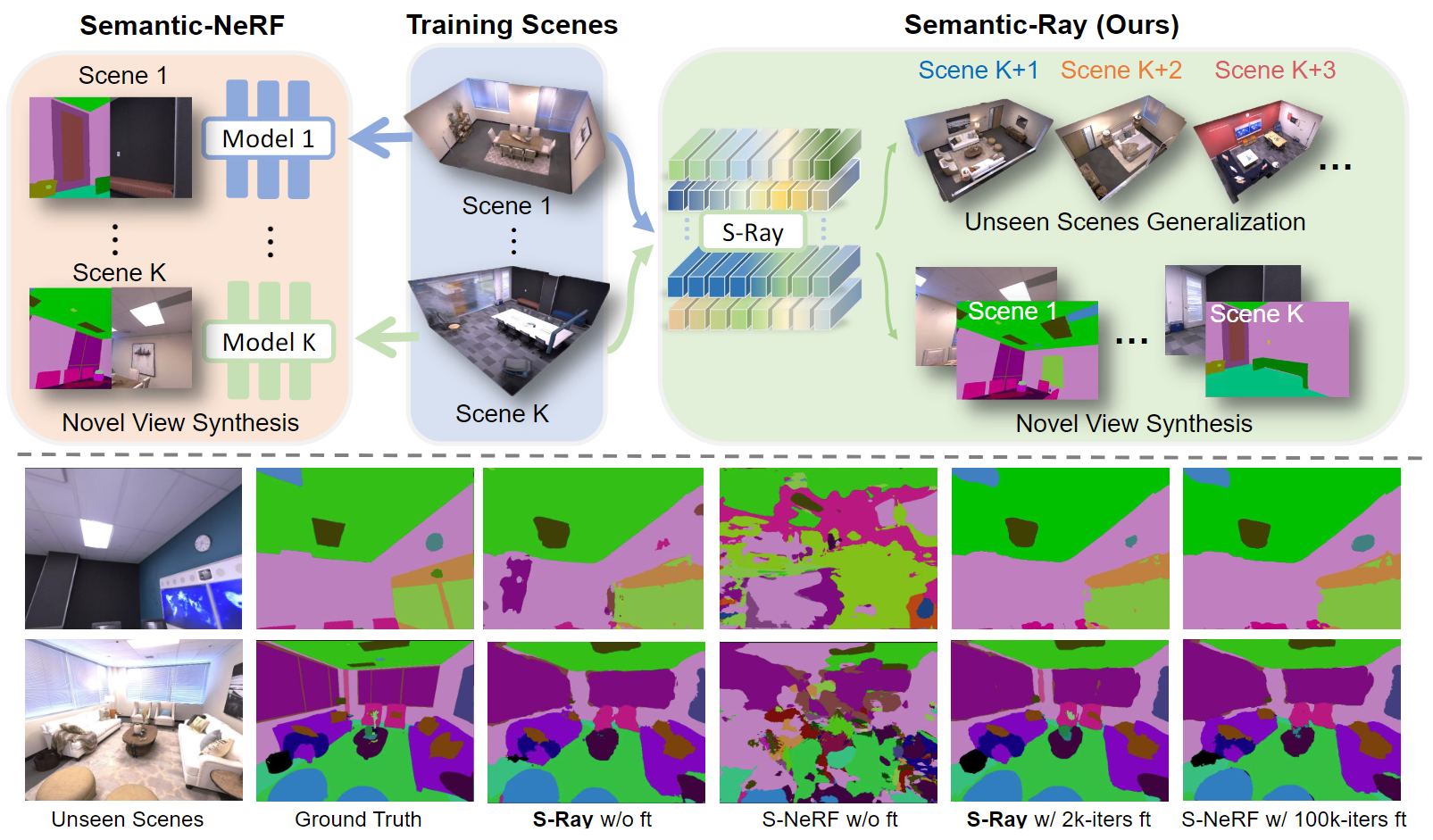
Top: Comparisons between Semantic-NeRF and our method Semantic-Ray. Semantic-NeRF (S-NeRF for short) needs to train one independent model for each scene,
while our Semantic-Ray (S-Ray for short) is able to simultaneously train on multiple scenes and generalize to unseen scenes. Bottom: Experimental comparisons
between S-Ray and S-NeRF on generalization ability. We observe that our network S-Ray can effectively fast generalize across diverse unseen scenes while S-NeRF
fails in a new scene. Moreover, our result can be improved by fine-tuning on more images for only 10 min (2k iterations), which achieves comparable quality
with the Semantic-NeRF's result for 100k iterations per-scene optimization.
Method
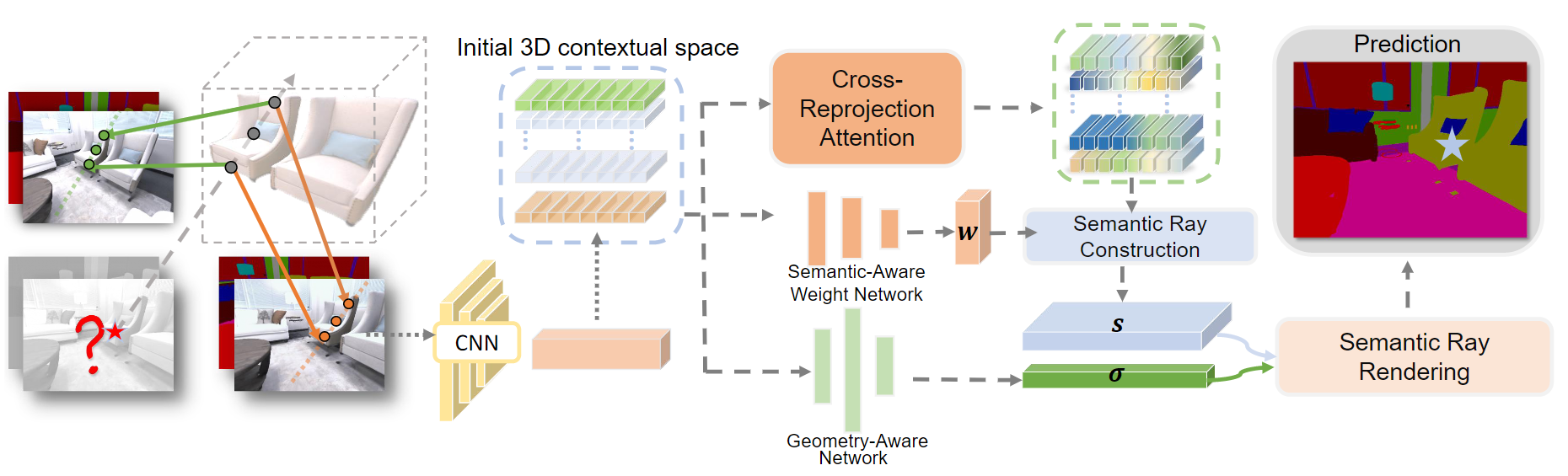
Pipeline of semantic rendering with S-Ray. Given input views and a query ray, we first reproject the ray to each input view and apply a CNN-based module to
extract contextual features to build an initial 3D contextual space. Then, we apply the cross-reprojection attention module to learn dense semantic connections
and build a refined contextual space. For semantic ray rendering, we adopt the semantic-aware weight net to learn the significance of each view to construct
our semantic ray from refined contextual space. Finally, we leverage the geometry-aware net to get the density and render the semantics along the query ray.
Cross-Reprojection Attention Module
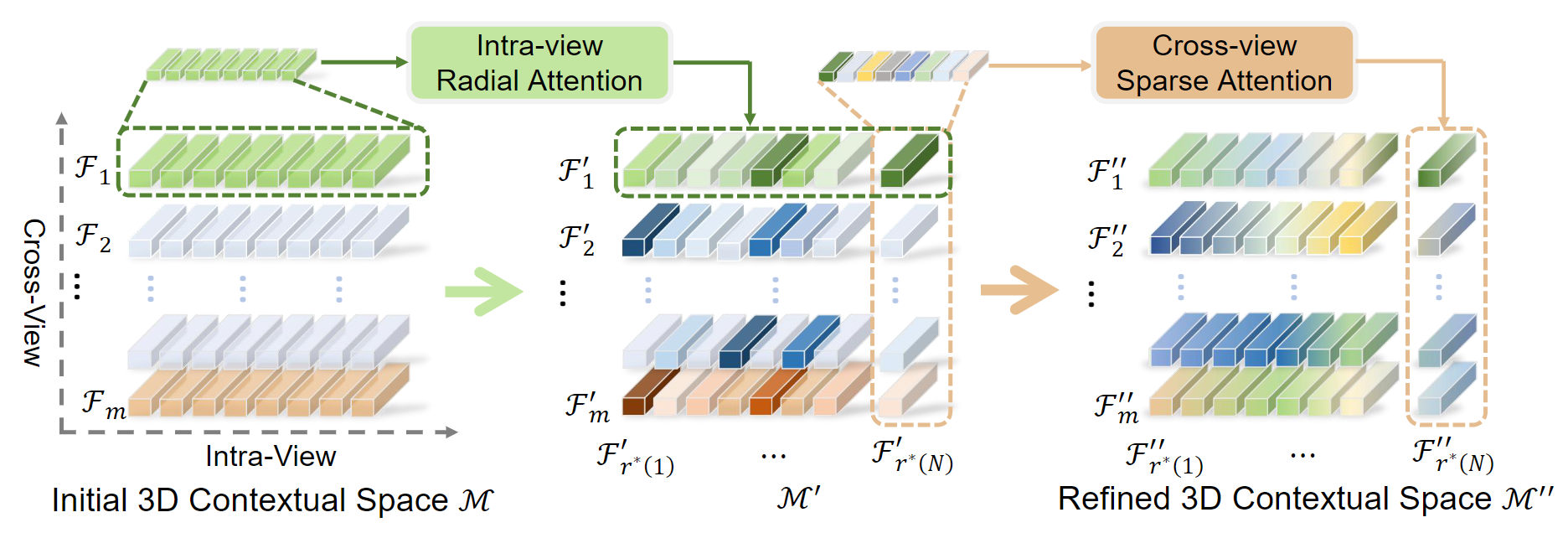
Pipeline of Cross-Reprojection Attention. Given the initial 3D contextual space, we first decompose M along the
radial direction (i.e., each intra-view). Then, we apply the intra-view radial attention module to each Fi (i=1, …, m) to learn the
ray-aligned contextual feature from each source view and build the M′. We further decompose the M′ cross multiple views and
employ the cross-view sparse attention module to each F′r*(i), thus capturing sparse contextual patterns with their respective
significance to semantics. After the two consecutive attention modules, we fuse the decomposed contextual information with the final refined 3D contextual
space M′′, which models dense semantic collections around the ray.
Experiments
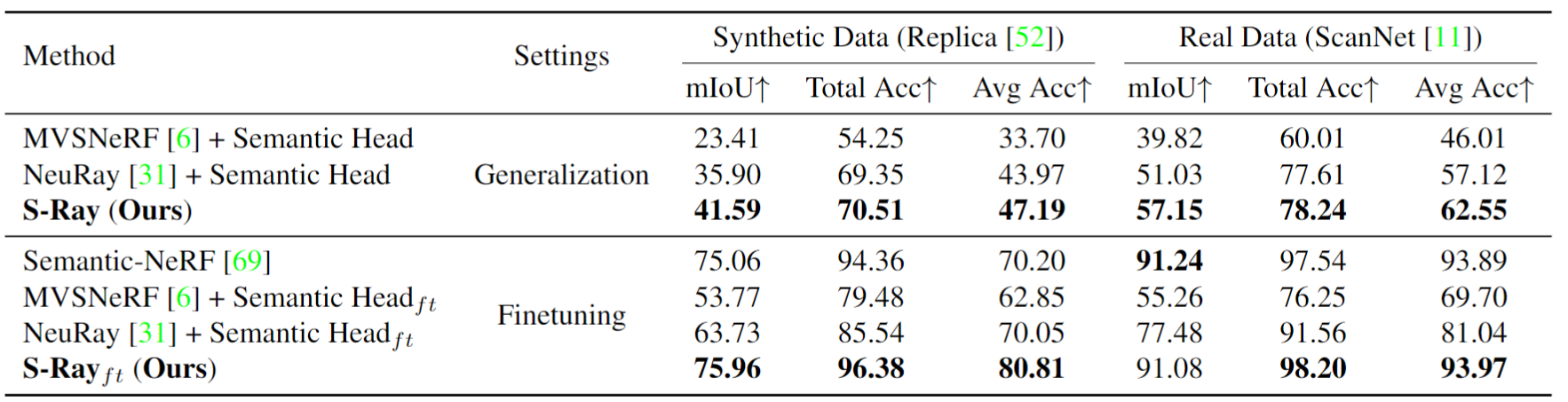
Quantitative comparison. We show averaged results of mIoU, Total Accuracy, and Average Accuracy (higher is better) as explained in
Section 4.1 of the paper. On the top, we compare S-Ray (Ours) with NeuRay+semantic head and MVSNeRF+semantic head with direct network
inference. On the bottom, we show our results wiht only 10 minutes of optimization.
Qualitative results on ScanNet and Replica dataset. The following are the visualization results of our Semantic Ray (S-Ray) on Replica and ScanNet datasets. On the left, we show the ground truth
of test scenes (i.e., unseen scenes) and the rendering results of our method. On the right, we show the direct and 10min fine-tuning semantic
rendering results by S-Ray. Our Semantic Ray can fully exploit contextual information of scenes, which presents strong generalization ability
to adapt to unseen scenes. Our performance in radiance reconstruction shows the potential of our attention strategy, which is able to learn
both dense contextual connections and geometry features with low computational costs.
Conclusion
In this paper, we have proposed a generalizable semantic field named Semantic Ray, which is able to learn from multiple scenes and generalize
to unseen scenes. Different from Semantic NeRF which relies on positional encoding thereby limited to the specific single scene, we design a
Cross-Reprojection Attention module to fully exploit semantic information from multiple reprojections of the ray. In order to collect dense
connections of reprojected rays in an efficient manner, we decompose the problem into consecutive intra-view radial and cross-view sparse
attentions, so that we extract informative features at small computational costs. Experiments on both synthetic and real scene data
demonstrate the strong generalization ability of our S-Ray. We have also conducted extensive ablation studies to further show the
effectiveness of our proposed Cross-Reprojection Attention module. With the generalizable semantic field, we believe that S-Ray will encourage
more explorations of potential NeRF-based high-level vision problems in the future.
Bibtex
@inproceedings{liu2023semantic,
author = {Liu, Fangfu and Zhang, Chubin and Zheng, Yu and Duan, Yueqi},
title = {Semantic Ray: Learning a Generalizable Semantic Field with Cross-Reprojection Attention},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
 Paper (arXiv)
Paper (arXiv)
 Code (GitHub)
Code (GitHub)